Scraper
Scraper
Build a massive documentation corpus on a topic — automatically.
Multi‑criteria search, source selection, AI pre‑crawl, quality scoring, then full crawl: Scraper turns the web into hundreds of clean pages ready for AI and RAG (including Nexus).
Need a large corpus of data on a topic?
Result: a reliable, usable, industrial‑grade corpus.
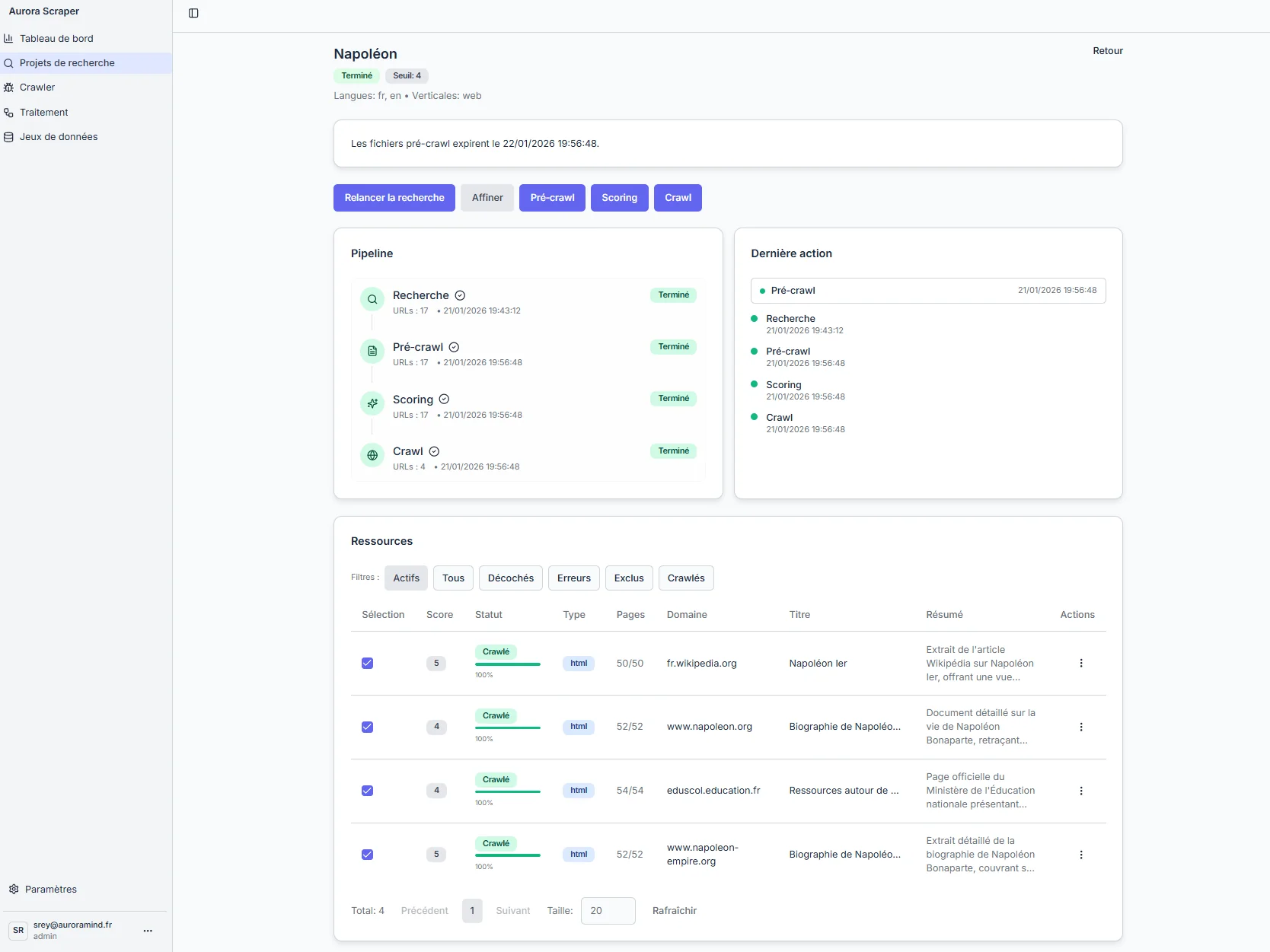
Three pillars
Smart selection
Not all sources are equal: Scraper filters and prioritizes.
Measurable quality
Pre‑crawl + AI scoring, automated = clear, traceable decisions.
AI / RAG‑ready
Clean, normalized pages that are easy to index.
The web is massive, but good content is rare.
Finding sources, qualifying them, cleaning and structuring them is too costly. Scraper turns this into a reliable pipeline.
Without Scraper, the corpus is noisy and incomplete.
What you get
Research projects
One project = one topic, multiple qualified sources, full crawl.
Clean corpus ready to ingest
Depending on your choice, hundreds of cleaned, structured .md pages ready for Nexus, another RAG, or any other application.
Full traceability
Each page is linked to its site, score, and decision.
Simple in 5 steps
Multi‑criteria search
Web sources + news + videos, with filters and parameters.
AI pre‑crawl
Quick sampling by an AI model to judge the real relevance of a site.
AI quality scoring
Automatic score to select the best sources.
Full crawl
Multi‑page extraction per selected site.
Clean export
Cleaned pages ready for AI ingestion.
Who is it for?
Executives & business teams
- Build a reference corpus on a market or vertical
- Accelerate strategic and competitive monitoring
- Leverage reliable sources for faster decisions
AI / Data teams
- Feed a RAG with pages ready to index
- Automate source selection to avoid noise
- Control quality before ingestion (scoring + pre‑crawl)
Product / Documentation teams
- Build an external documentation base (products, standards, use cases)
- Automatically refresh useful sources
- Reduce manual collection time
Consultants / firms
- Industrialize information collection by sector
- Produce deliverables backed by a structured corpus
- Save time on exploratory research
AI agencies / studios
- Deliver enriched datasets to clients
- Launch multi‑source research on a topic
- Produce clean corpora for domain assistants
Research & innovation
- Build an external knowledge base
- Explore an emerging topic at scale
- Index reliable sources in a private RAG
Use cases
Encyclopedic corpus on a specific topic
Build a complete, structured reference for a domain (health, finance, energy, etc.).
External technical documentation
Standards and guides gathered into a single corpus, ready to ingest.
Competitive intelligence
Track products, announcements, and trends with filtered, scored sources.
Business knowledge base
HR, legal, industry, IT: centralize reliable, traceable sources.
Internal training
Select solid learning sources to build internal training paths.
Academic / scientific research
Collect publications and resources at scale.
Sector consolidation
Aggregate media, blogs, and specialized sites for a sector.
Multilingual collection
Feed international markets with high‑quality local sources.
Regulatory analysis
Laws, directives, recommendations: surface the essentials fast.
Commercial knowledge base
Market, clients, context: a base for sales and strategy.
Scraper feeds Nexus with RAG‑ready corpora.
Clean, structured sources that enrich your knowledge base and accelerate AI use cases.
Turn any topic into an AI corpus in a few clicks.
Scraper automates source selection and produces a clean corpus ready for AI and Nexus.